OpenAI filed confidentially for an IPO this week. Anthropic is right behind them. The two most prominent names in frontier AI are going public, and with that shift comes a fundamental change in how enterprises should think about model procurement.
As TechCrunch declared, the era of continuous model scaling is over. And if you're building production AI systems on a single model from a single provider, you're carrying more risk than you realize.
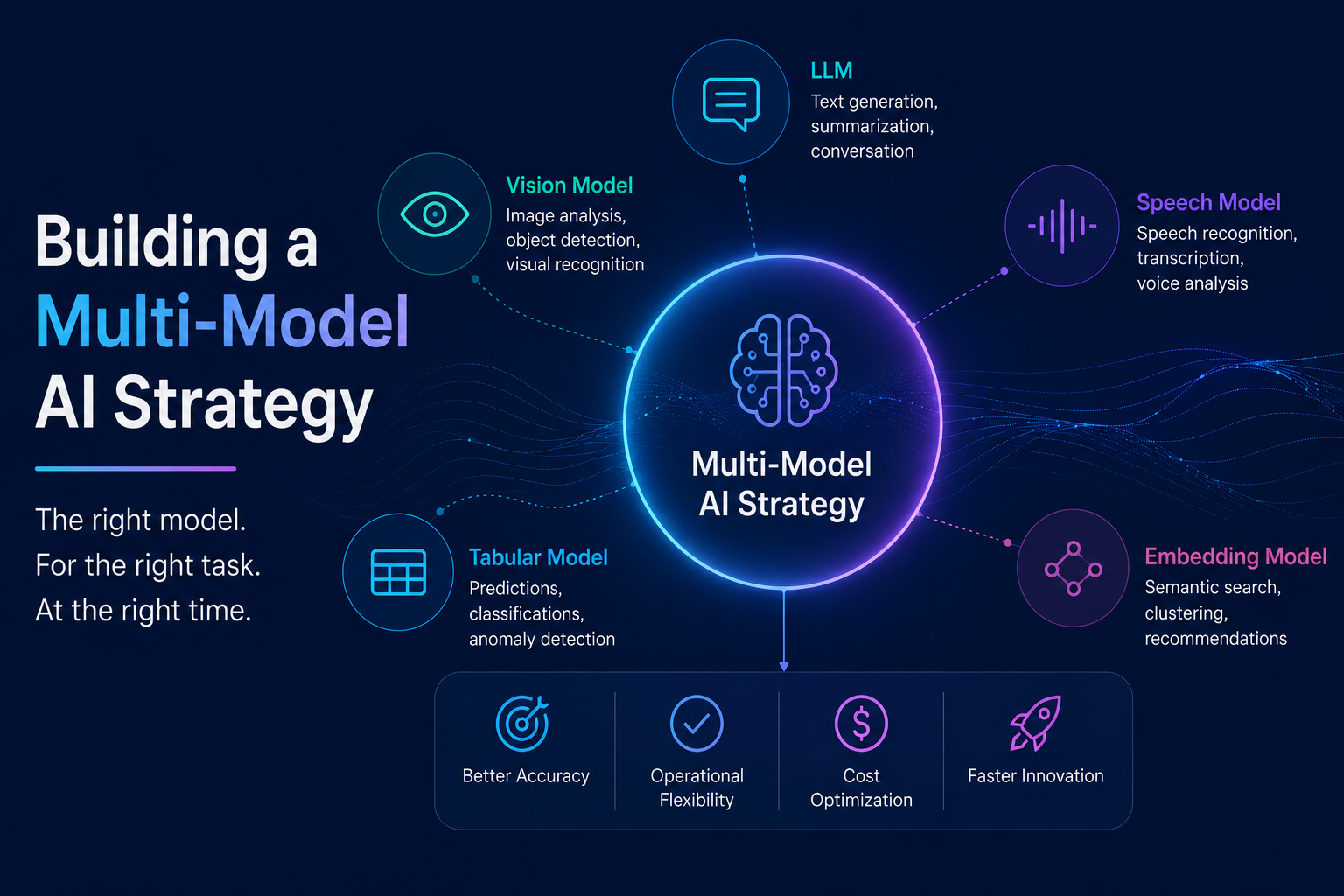
The Single-Model Trap
Most organizations that have moved beyond experimentation are running a single large language model for everything. Chat, summarization, classification, extraction, generation -- all through one API. It's easy to set up and it works well enough. But it's also expensive, brittle, and increasingly indefensible.
The problems with single-model architectures:
- Cost inefficiency -- You're paying frontier-model prices for simple classification tasks that a lightweight model could handle for pennies.
- Vendor lock-in -- A model provider's pricing shift, API change, or outage becomes your outage.
- Suboptimal output -- Models have genuine strengths and weaknesses. Using one for everything means accepting tradeoffs that a targeted approach wouldn't require.
- No redundancy -- When your single provider goes down (and they will), everything stops.
Pair Models to Tasks
The alternative is straightforward: match the model to the task. Not every job needs a $15/million-token reasoning model. Most don't.
A rational tiering looks something like this:
- Tier 1 -- Frontier Reasoning (OpenAI o-series, Anthropic Opus): Reserved for complex reasoning, multi-step agentic workflows, code generation, and high-stakes analysis. These are your most expensive calls per token, and they should be your scarcest.
- Tier 2 -- General Purpose (Claude Sonnet, Gemini Flash, GPT-4o): The workhorse tier. Structured output, summarization, content generation, tool use, most RAG queries. Balances capability and cost for the bulk of your traffic.
- Tier 3 -- Fast & Cheap (Claude Haiku, Gemini Flash Lite, GPT-4o Mini): Classification, extraction, routing, simple completions. Tasks where speed and cost matter more than reasoning depth. These should handle the majority of your call volume.
Build Price-Based Waterfalls
Task pairing gets you partway there. Price-based waterfalls get you redundancy and cost control at the same time.
The pattern is simple: for any given tier, maintain two or three interchangeable models. Route first to the cheapest option. If it fails (timeout, error, quality threshold not met), fall through to the next. The fallback acts as both a safety net and a pressure valve on cost.
Concrete example for Tier 2:
- Primary: Claude Sonnet (best price/capability ratio for most tasks)
- Fallback 1: Gemini 2.5 Flash (competitive capability, different provider = infrastructure diversity)
- Fallback 2: GPT-4o (third-provider safety net)
This isn't theoretical. We're seeing 30-50% cost reductions in production by routing the right tasks to the right models, with redundancy built in for free.
The Market Is Telling You Something
The OpenAI and Anthropic IPOs are a signal, not just a headline. Public market pressures will push these companies toward margin optimization. That means pricing changes, feature prioritization driven by shareholder returns, and platform shifts that may not align with your deployment timeline.
Enterprises that bet everything on one provider have already learned this lesson the hard way -- through pricing changes, API deprecations, and unexpected outages. The organizations that built multi-model architectures from the start weathered those events without missing a beat.
Where This Is Going
We're moving toward a world where model selection is handled by a routing layer -- not by developers hardcoding model names in application code. The routing layer will assess the request, check available models by tier, evaluate real-time pricing and latency, and make the call.
Some of the infrastructure for this already exists. LangChain, OpenRouter, and custom orchestrators are doing it today. The next evolution will be fully automated: cost-aware routers that learn which models perform best for which request patterns and adjust dynamically.
The companies that adopt this mindset now won't just save money. They'll build systems that are more resilient, more adaptable, and less dependent on any single provider's roadmap. In a market that's changing as fast as this one, that optionality is the point.
FutureInSites helps companies design and implement multi-model AI architectures. We assess your current stack, identify the right tiering strategy, and build the routing and monitoring infrastructure to run it in production. Get in touch if you're ready to move beyond the single-model approach.